I spent most of the week in a deteriorated state. Getting over the 12 injections last Friday took much longer than expected. It still amazes me how much work I can do with a disability, medications that slow me down, and a lack of sleep (Max started Kindergarten this week).
In a way, this is a lot like our systems, overtaxed by the increasing number of people using them. Ready to both be upgraded by an admin and taken down by a deluge of traffic at the same time (or worse, the opposite). Running along in a less than optimal state is pretty optimal for a lot of workloads. Sure, specific workloads will need certain kinds of hardware, and the software varies in those spaces. But, most of us are still using an abstraction of an abstraction of an abstraction (of an abstraction).
Like a top starting to lose its grip on centrifugal force, our systems run fine until they don’t. Now, more than ever, we need to know how the systems are performing. What caused the slowdown? What sent the system sliding off the table into oblivion? Will it be able to be spinning like a top again soon? What do you do to pick it back up and having it moving like the top in Inception? All these questions are answered by the same question: How do we know if we’re doing the right thing?
If you’re doing the right things, the system will bounce back resiliently, knowing that maybe that AZ is having a bad day, the direct connect isn’t the fastest route anymore due to an upstream provider mistake, or the system is in a state its never experienced before. If you’re doing the right things, downtime is minimal. Services impacted are few. Dollars lost are low. This reminds me, if you don’t know how much your organization is losing by any given system outage, you might not be doing the right thing.
But, how the team moves forward is a series of steps that eventually lead to the right thing to do to fix the system. If you’re ever stuck troubleshooting, ask yourself, “How do we do what’s right here?” Reset the situation in your mind. Find the point of failure by starting from the closest thing to the failure and eliminating what’s working from the list. Verify they’re working. Trust but verify. You can get to the right thing by process of elimination sometimes too.
People
What it’s like to be an older worker in tech
“[M]anagement should be careful about sanctioned post-work ‘fun,’ since a lot of it isn’t very inclusive. ‘There might be single moms who can’t stay after work, or somebody with a disability who can’t do whatever the fun physical game is.’”
Declarative Cloud Infrastructure Management with Terraform
100 Million Downloads and Over 5,000 Ecosystem Add-Ons later, Hashicorp has released the 1.0 version of Terraform. This eBook and audiobook will help you understand the underlying concepts of this infrastructure as a code tool and how it can be a significant resource when your cloud infrastructure hits critical mass. SPONSORED
Reducing sugar in packaged foods can prevent disease in millions
Let’s talk about REAL scale with REAL human impacts.
KBE Insider (Ep 3): Luke Hinds
“We talk to Luke Hinds, Security Lead for Office of CTO, Red Hat, about his work on the Kubernetes Security Response Team (CNCF), Sigstore, and the Kubernetes Hackerone Bug Bounty program. Sigstore was the topic of a recent Wired story. Luke is involved in many other projects and hobbies. KBE Insider, hosted by CNCF Ambassador Chris Short and Developer Langdon White, lets you reach people deeply involved with Kubernetes, hear what they have to say, and interact with Kubernetes experts from across the globe.”
Chinese developers protested insanely long work hours. Now the nation’s courts agree
“‘996’ culture and its assumption of six twelve hour days - without overtime - labelled abusive and illegal”
It is time to say Goodbye!
This is why I said, “When the government is done with me, I’m done with government work.”
Process
Why are hyperlinks blue?
“April 12, 1993 – Mosaic Version 0.13” The standard you create today could outlive you.
Infrastructure as Code Automation for Terrafrom and GitOps workflows
Code, No Manual Processes. Automate Terraform tasks, reduce errors and drifts, improve security and auditability of your infrastructure. env0 automates and simplifies the provisioning of cloud deployments for Terraform, Terragrunt and GitOps workflows. SPONSORED
“Worst cloud vulnerability you can imagine” discovered in Microsoft Azure
“Access to a Cosmos DB instance’s primary key is ‘game over.’ It allows full read, write, and delete permissions to the entire database belonging to that key. Wiz’s Chief Technology Officer Ami Luttwak describes this as ’the worst cloud vulnerability you can imagine,’ adding, ‘This is the central database of Azure, and we were able to get access to any customer database that we wanted.’”
T-Mobile hacker explains how he breached carrier’s security
“‘I was panicking because I had access to something big,’”’ he wrote in Telegram messages to the Journal. ‘Their security is awful.’” Good lord. It’s T-Mobile’s third breach in two years.
Billions of devices impacted by new BrakTooth Bluetooth vulnerabilities
“[R]esearch found that the same Bluetooth firmware was most likely used inside more than 1,400 chipsets, used as the base for a wide assortment of devices, such as laptops, smartphones, industrial equipment, and many types of smart “Internet of Things” devices.”
Tools
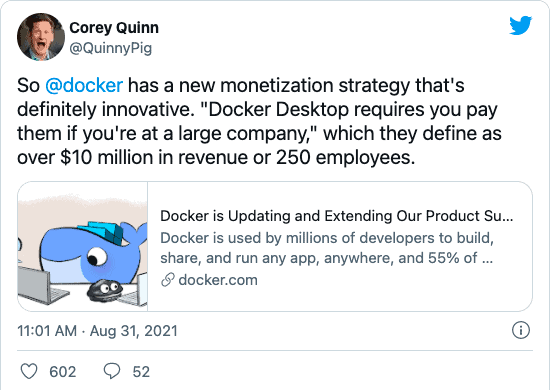
Docker Desktop no longer free for large companies: New ‘Business’ subscription is here
The blow hole sounds of desperation.
‘Migrating from Docker to Podman’ by Marcus Noble “Docker has recently announced that Docker Desktop will soon require a subscription and, based on the size of your company, may require a paid subscription. (It remains free for personal use).”
Manage incidents directly from Slack 🧑🚒
Rootly helps automate the tedious manual work like creating incident channels, searching for runbooks, documenting the postmortem timeline, and more. Teams sized 20 to 2000 manage hundreds of incidents daily and save thousands of engineering hours a year within Rootly. Get started in <5min or book a demo to learn more and get Starbucks ☕ on us! SPONSORED
API deprecation in Kubernetes 1.22 that will impact your operators
“The CRD update is expected to be the change that will affect most [community and] partners [operators]. The good news is that it’s really easy to make this update because the stable API is almost identical to the one you’re already using – it just requires a small code update.”
A Kubernetes engineer’s guide to mTLS
“Mutual authentication for fun and profit”
Linux 5.14 SSD Benchmarks With Btrfs vs. EXT4 vs. F2FS vs. XFS
Which filesystem should you use for your needs?
Five Ansible Techniques I Wish I’d Known Earlier
“If you’ve ever spent ages waiting for an Ansible playbook to get through a bunch of tasks so yours can be tested, then this article is for you.”
Linux/BSD command line wizardry: Learn to think in sed, awk, and grep
“‘Do people really write these long, convoluted commands?’ In a word: yes.” I’ve got some real doozies in my notes. Trust me sort | uniq -c | sort -n is handy too.
Comparing Open Source BGP stacks with internet routes
I love this comparison. BGP is so handy so knowing which implementation to use is a big deal.
Release NGINX Ingress Controller - v1.0.0 · kubernetes/ingress-nginx
“Ingress NGINX v1.0.0 is HERE! With support for Kubernetes v1.22 and dropping support for v1beta1!”
run-x/awesome-kubernetes
“A curated list for awesome kubernetes projects, tools and resources.”
uutils/coreutils
“Cross-platform Rust rewrite of the GNU coreutils”
borjatur/kubernetes-using-ansible-vagrant
“Kubernetes Setup Using Ansible and Vagrant”
tiny-http/tiny-http
Low level HTTP server library in Rust
DevOps’ish Tweet of the Week
Want more? Be sure to check out the notes from this week’s issue to see what didn’t make it to the newsletter but are still worth your time.